
Enhancing Underwriting Efficiency for Corporate Loans using RAG based AI Solutions
AI USE CASES FOR: BANKING | LENDING

Background
Unlike Retail Loans, underwriting loans to companies is a lengthy process involving considerable paperwork, data crunching, and manual processes. This is because the risks underwritten and the ticket sizes involved in such wholesale (corporate) loans could be substantially higher.
Consequently, while the risks involved in retail loans could be monitored at a portfolio level, corporate loans require risks to be managed at a much more granular level (i.e., loan or customer level). This directly impacts the level of automation that could be incorporated in managing the loan lifecycle (Sourcing, Underwriting, Monitoring, and Collections) for the two different categories of loans (viz. retail and wholesale).
Notably, while various off-the-shelf software solutions are available for automating and streamlining the lifecycle of retail loans, the availability of such off-the-shelf solutions is restricted for wholesale loans (often requiring a good amount of customization).
This article describes some of the key issues relating to the underwriting of wholesale loans and prescribes RAG (Retrieval-Augmented Generation) based solutions to overcome the limitations.
Corporate Loan Underwriting/Credit Appraisal
Corporate credit appraisal/Underwriting is the process of evaluating a company's creditworthiness to determine its ability to repay a loan or meet financial obligations. It involves analyzing financial statements, cash flow, debt levels, audit reports, market data, corporate actions, group support, industry risks, management reports, statutory filings, and management quality. Typically, this data is collated from various sources.
Lenders use this assessment to gauge the risk of lending to a corporation, set loan terms, and decide whether to approve financing. The process ensures informed decision-making by balancing potential returns against the risk of default.
Managing Wholesale Loans: Issues with the current model
Highly Manual Process: Involving steps like analysis of unstructured data sources such as Financial Statements, Management Discussions from the Annual Report, Audit Reports, and Statutory Filings
Compilation of data: Data needs to be compiled from various structured sources (such as Customer Data from Core Banking, Collateral Systems) and Unstructured Sources (of the nature mentioned above) for analysis and presentation for approvals, etc.
Document Driven: Typically, such analysis is carried out using templates such as an Excel sheet-based ‘spreading’ or memos/proposals for approvals; considerable time is spent in filling in the spreadsheets or preparing approval notes.
Error Prone: Such a process is error-prone and has low fault tolerance (E.g., copy + paste errors); hence, additional layers of process controls, such as maker-checker/approvals, need to be built into it.
Inability to take automated action: In most cases, the action is outside of the process; For example, approvals need to be initiated/triggered (manually) through memos, etc., instead of being automatic
Limited Memory: Because the process tends to be predominantly manual, vital information is largely in paper form, which has limited institutional memory
Having looked at some of the issues involved in the appraisal of corporate loans, let us look at how RAG-based AI solutions can provide a better alternative to overcome the limitations.
RAG: In a nutshell
Let’s try to understand RAG in a non-technical manner. For this, we need to understand a key limitation of LLMs first and then look at how RAG overcomes this.
Models such as LLMs (i.e., Large Language Models) work on vast pre-trained data, meaning the model’s output is contextual to/dependent on the data on which it was trained. For example, suppose you were to ask Chat-GPT (which is an LLM) on queries relating to your company’s internal processes; the model may either hallucinate or not give an output, as the model has not been trained with data about your company’s policies.
In short, traditional LLMs (such as GPT-4o, LLaMA 3, Claude 3, Grok 3, Gemini) are constrained by the data on which they have been pre-trained.
This limitation does not permit their usage for wider applications such as querying based on internal/private data (i.e. data which are not publicly available); for example, a pure Chat-GPT-based chat-bot for a banking product support may not yield the best results as the customer query would always be related to the specific banking product (such as the ROI, repayment, charges, penalty, waiver)
Now, what if an LLM could be trained using internal/private/personalized data such as corporate policies, financials, and internal reports (such as audit reports).
RAG models have evolved to solve this limitation. In simple terms, Retrieval-Augmented Generation (popularly called RAG) enhances the capabilities of AI-based models by letting them pull information from contextualized sources to provide answers that are more accurate and relevant, especially for specific topics.
To give a more formal definition, Google Cloud defines RAG as “Retrieval-augmented generation (RAG) is an architecture that augments the capabilities of a large language model (LLM) by combining a retrieval step that uses the user prompt to fetch relevant external data with the generation step of an LLM to produce a response grounded in that data.”
Those interested can also go through IBM’s details on RAG and their relevance here: https://www.ibm.com/think/topics/retrieval-augmented-generation
How can RAG solve the problem?
Having understood what RAG is, I propose the following framework on how RAG can address the issues with the current process for corporate loan underwriting:
Suggested Framework (Please refer to details of steps outlined below)
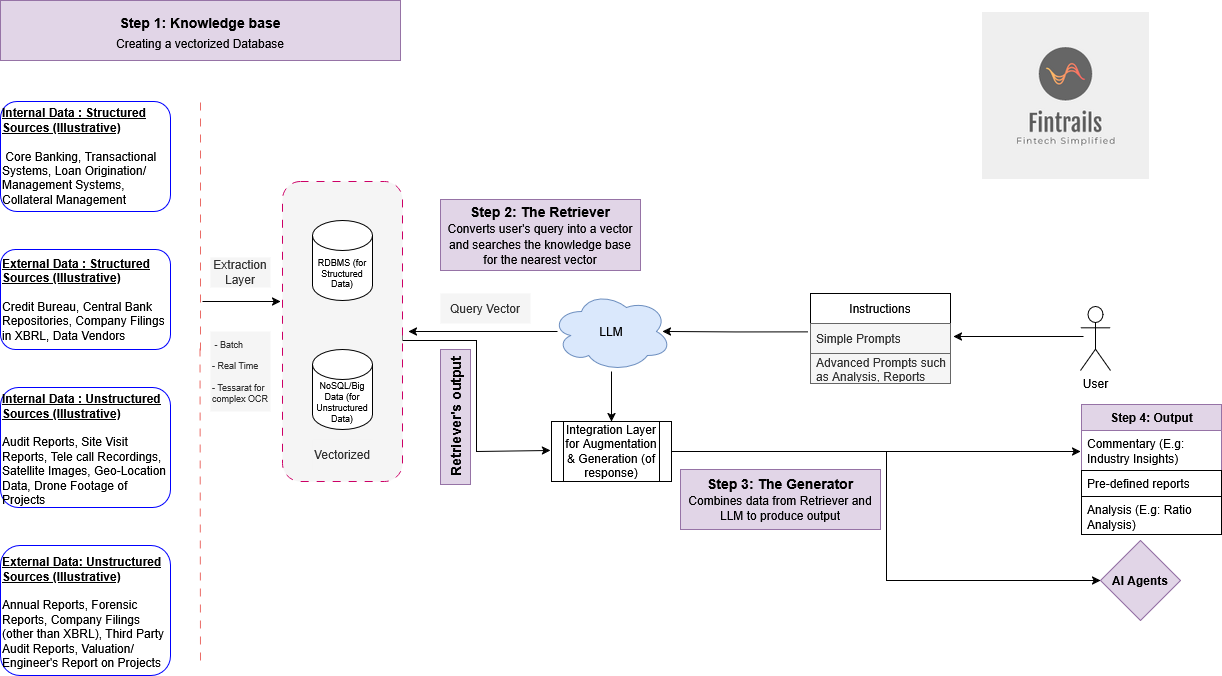
Step 1: Creating the ‘Knowledge Base’
The first stage in constructing a RAG-based architecture is to create a Knowledge Base.
Such a knowledge base could consist of data from structured sources (Like customer data from Core Banking Systems and other internal systems, such as Loan Management and Collateral Systems). It could also contain structured data from external sources such as Credit Bureau, Repositories, XBRL-based Corporate Action Data, Ratings, and Market Data.
Unstructured data, such as PDF copies of annual Reports, audit reports, images from site visits, and geo-location data, could be extracted using appropriate technologies such as Tesseract. These data can then be vectorized (converted into numerical representations in a multidimensional mathematical space through a process called as ‘embedding’) and stored in the ‘Knowledge Base’.
This process prepares the ‘Knowledge Base for semantic vector search (a form of search in which a similarity is established between the user’s query (or prompt) and data from the unstructured sources through a distance measurement (called Euclidean distance or cosine similarity).
In short, this is a preparatory stage to convert information from various sources into a powerful, searchable/queryable repository.
Illustrative Use Case: Let us consider a use case where Corporate Loans need to be appraised (underwritten) by a commercial bank.
A traditional approach would involve collating data from different sources such as existing limits, outstanding, transaction details from Core Banking, rating/scores from rating systems, and financials from company reports. Numbers from each of these sources need to be collated, ratios calculated, and a commentary written highlighting factors such as company/industry/group performance, financial risks, and other risk factors
In a RAG approach, all relevant data would be extracted using an appropriate technology (such as ETL, API, or Parsers), vectorized, and stored in a suitable database. This would become our ‘Knowledge Base’.
Step 2: Retriever
In this step, the user’s query (prompt or instructions) is also converted into a vector (numerical representations in a multidimensional mathematical space through a process called ‘embedding’).
Once a similarity is established between the user’s query vector and the knowledge base vector (through an appropriate mathematical approach), the relevant data from the knowledge base is retrieved and passed on to the next stage.
Illustrative Use Case: A user would construct/engineer an appropriate prompt and query the database with specific instructions to retrieve the desired data (such as financials), analyze it (such as prepare ratio/trend/cashflow analysis), and write a commentary based on the study.
The Retriever would convert the query into a vector and search for the closest available vectors from the knowledge base. Once the nearest vectors are arrived at, the retriever passes on the facts and analyses to the next step (The Generator)
Step 3: The Generator
In this stage, the RAG model combines the data analysed by the ‘Retriever’ from the ‘Knowledge Base’ along with the LLM Model (described above) to produce more meaningful and contextual results.
Illustrative Use Case: In our use case, the Generator would combine the data and analysis performed by the Retriever and combine it with an LLM model, to produce insights such as industry analysis, risk factors, etc.
Step 4: Output
The outcome can be passed on to an appropriate output mode for a ‘human-in-the-loop’ vetting.
Alternatively, the outcome can be used to trigger Agents for further action, such as for triggering approval workflows, reports etc.
Benefits
Achieve a high level of automation for process efficiency - Manual tasks such as data collation from vast sources can be automated
Greater accuracy
Human-in-loop can be incorporated for oversight
Institutional memory and an audit trail of all actions can be maintained
Conclusion
RAG-based AI Solutions, built on AI platforms such as Langchain, can significantly reduce manual processes and bring in process and cost efficiency for the corporate loan underwriting process. In turn, this can improve the overall profitability and transparency of banking operations.