
Knowledge Graphs for Banking AI: How Connected Data Gives LLMs a Memory
Part of the series: Assessing Data Pipelines for AI Readiness | Pillar II — The Context Layer, continued

In my previous article on Banking Ontology: The Semantic Layer Your AI Strategy Can’t Ignore, we looked at the first part of the context layer. In this article, we look at the next building block of the context layer - Knowledge Graphs.
An Ontology defines the schema of possible relationships, such as the permitted entity types and the relationship types between them. A Knowledge Graph instantiates that schema with real data.
Consider a scenario: A relationship manager asks the bank’s AI assistant: “What is our total exposure to this corporate group?” The system returns a number with confidence, but only that the number is wrong, not because the data does not exist, but because the AI has no way of knowing that there are three subsidiaries of the corporate groups - its two SPVs, and a holding company registered in a different jurisdiction; all part of the same group risk exposure and hence exposures need to be consolidated. In short, the AI model (like an LLM) does not have a context about the definitions and regulations relating to aggregating group exposures.
This is not a data quality problem. The data exists across the bank’s systems. In the absence of a context, the LLM lacks the ability to correlate different datasets. This precisely what Knowledge Graphs are designed to solve.
In the previous article, we established that a banking ontology defines what data means, providing every AI system with a shared vocabulary for concepts such as customer, counterparty, and exposure.
A Knowledge Graph takes the capabilities to the next step: it maps how everything is connected.
Why RAG Alone Is Not Enough
Typically, AI pilot programs at most financial institutions begin with Retrieval-Augmented Generation, or RAG. The idea is straightforward: rather than relying solely on what an LLM learned during the training process, relevant documents (such as Regulations, Policies, Memos, Approvals & Emails) are retrieved from internal sources at query time and fed to the model along with the question (prompt). The LLM then generates a response grounded in the actual data (from the documents) rather than general inferences obtained through training.
Even though this is a genuine improvement over an ungrounded model, RAG has a structural limitation that becomes apparent the moment a question requires reasoning across relationships (such as between entities) rather than documents.
RAG retrieves discrete segments of text based on semantic similarity, without an understanding of how entities are interrelated. It is unable to trace ownership structures, such as those connecting a parent company to its subsidiaries or to dormant special purpose vehicles (SPVs).
Additionally, RAG cannot establish links between transactions across business lines, such as associating a trading book transaction with a credit facility in the lending system or a contingent liability in treasury. Its retrieval process is driven by similarity, rather than by actual connections within the data.
Three limitations of vanilla RAG are worth noting here:
It treats every document as an independent unit, with no awareness of the entities within them and how those entities link across systems.
It cannot construct multi-hop reasoning chains, such as identifying and describing that A owns B, which transacts with C, which is flagged against a sanctions list.
It has no structural model of the bank’s data, so it cannot know what it does not know.
In short, RAG gives the LLM relevant content from the documents. A knowledge graph gives it a navigable model of the bank’s reality.
What a Knowledge Graph Actually Is
A Knowledge Graph is a structured network of entities and the relationships between them.
In a banking context, entities include customers, legal entities, accounts, products, transactions, and jurisdictions. The entities are connected through edges that describe their relationship, such as owns, transacts with, is a subsidiary of, is exposed to, is regulated by, and is a director of.
In this context, it helps to understand the differentiating factors of the Knowledge Graph from terms, often confused with:
A relational database stores rows and columns efficiently but treats relationships as join conditions, not as first-class objects. Querying multi-hop relationships across a relational schema is slow, brittle, and requires an analyst to know exactly what they are looking for before they can look.
A data dictionary defines what terms mean. It does not map how entities actually connect in practice across the institution.
An ontology defines the schema of possible relationships, such as the permitted entity types and the relationship types between them. A knowledge graph instantiates that schema with real data.
The Ontology says: a Customer can be linked to Related Parties. The Knowledge Graph says: this customer is linked to these three entities, with these ownership percentages, in these jurisdictions, as of this date.
This distinction matters for AI - An LLM querying a knowledge graph is not pattern-matching against text - it is navigating a verified, structured model of the bank’s actual relationships, which is a fundamentally different and more reliable form of reasoning.
Graph RAG in Practice: The Counterparty Risk Scenario
To make this concrete, consider a scenario that sits at the intersection of credit risk, treasury, and regulatory reporting, which almost every institution struggles with.
Scenario: A credit analyst asks the AI: “Summarise our total risk exposure to the Conglomerate X group.”
Without a Knowledge Graph, the system retrieves data points mentioning Conglomerate X and generates a summary. It captures the direct lending exposure recorded under that name. It may miss the subsidiary two levels down that holds a derivatives position in the trading book. It may miss the pension fund that is simultaneously a customer and a counterparty. It may also miss the SPV incorporated in a separate jurisdiction whose parent entity is Conglomerate X.
Output without Knowledge Graph: “Total exposure to Conglomerate X is approximately $240M across lending and treasury.”
With Graph RAG (RAG + Knolwedge Graph), the same query triggers a fundamentally different process:
The system identifies the pivot entity, in our illustration, Conglomerate X, and traverses the knowledge graph to surface all connected nodes: subsidiaries, associated legal entities, related accounts, product holdings, and flagged relationships.
The graph pulls a connected subgraph of the entire corporate structure as the bank knows it across all systems.
RAG then fetches relevant policy documents, credit agreements, and risk assessments linked to those specific entities
The LLM reasons over both the graph context and the document context, generating a response that is complete, structured, and traceable
The analyst can inspect the graph visually, verify the entity connections independently, and trace every figure back to its source system and date.
Ouput with Graph RAG: “Total exposure to the Conglomerate X group is $347M, comprising $240M direct lending facility (ref: credit agreement dated [date]), $82M mark-to-market derivatives exposure via Subsidiary Y, and $25M contingent liability through SPV Z incorporated in [jurisdiction]. All figures as of [date]. Sources cited.”
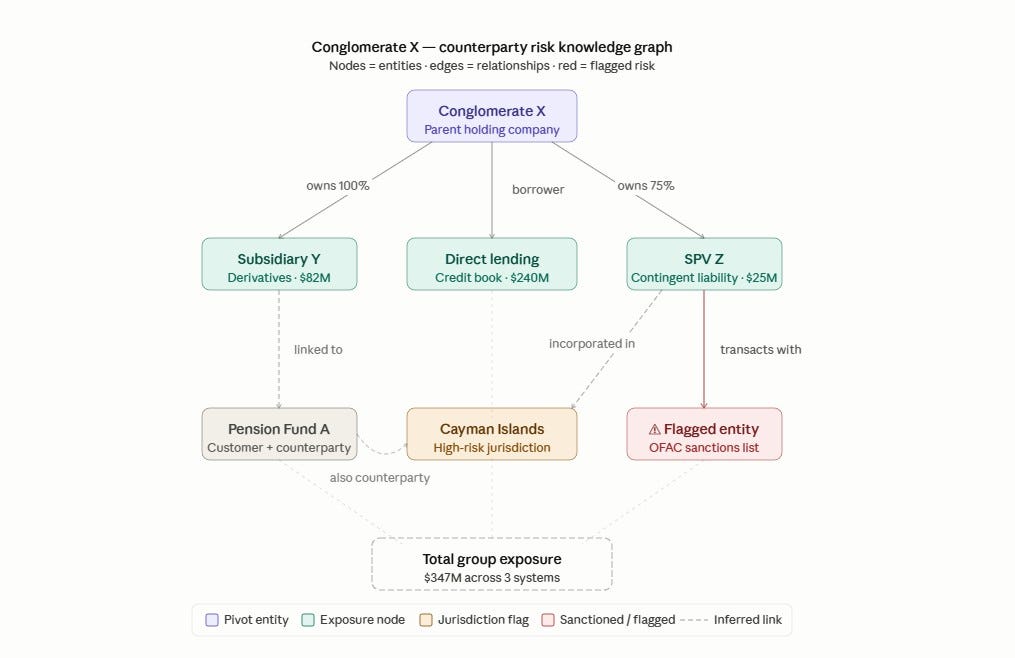
Thus, with Knowledge Graph, the shift is from probabilistic summarisation to deterministic tracing from what the model thinks is plausible to what the data actually shows.
Three Banking Use Cases
The counterparty risk scenario is illustrative, but knowledge graphs have structural value across multiple banking functions.
Regulatory Reporting and Data Lineage
Every data point in a capital adequacy or liquidity report can be traced back through the Knowledge Graph to its source entity, transformation step, and timestamp. This is the kind of data lineage that regulators are demanding under frameworks like BCBS 239 and that graph-based architectures provide structurally, not as an afterthought. When an auditor asks, “Where did this number come from?”, the answer should be completely traceable as a lineage.
Relationship Banking and Client Intelligence
A relationship manager serving a large corporate client typically has limited visibility into what other parts of the bank hold with that client’s subsidiaries, associated individuals, or related entities. A Knowledge Graph surfaces those connections across the institution, enabling the RM to walk into a conversation with a genuinely complete picture of the relationship and to identify cross-sell or risk concentration signals that would otherwise remain invisible.
Product and Regulatory Scope Analysis
When a new regulation or capital requirement is announced, the question “which of our products and customers fall within scope?” is difficult to answer based on a fragmented data landscape. A Knowledge Graph that links products to customer segments, to jurisdictions, to regulatory classifications makes that question answerable in hours rather than weeks.
The Implementation Reality
Knowledge Graphs are not just as a technology purchase. Building a trustworthy Knowledge Graph from legacy banking data is a significant data engineering and governance commitment.
In this regard, the following points are to be noted:
The quality of the graph is entirely dependent on the quality of the ontology beneath it. A Knowledge Graph built on unresolved semantic inconsistencies, where “counterparty” means different things in different systems, inherits those inconsistencies and amplifies them. This is why the previous article in this series matters: the ontology is the prerequisite, not an afterthought.
The right starting point is to be the scope limited. A single, high-value domain, counterparty risk aggregation, a single product hierarchy, and a defined regulatory reporting scope are better targets than an enterprise-wide graph on day one. In short - Build, Prove Value and Extend.
The human challenge is as real as the technical one. Knowledge graphs require cross-functional agreement on what the edges mean, the legal entity ownership chain agreed between legal, risk, and operations, not just the version that happens to be in one system. This requires the same governance conversation that the ontology demands, now applied to the connected data layer.
Banks that work through these challenges are not just solving today’s reporting problem. They are laying the a solid foundation for the agentic AI systems that will run multi-step workflows, not just answer questions, and that requires a navigable, reliable model of the institution.
To Conclude
The Ontology gave the bank’s AI a shared vocabulary. The Knowledge Graph gives it a connected model of reality.
Together, they form the semantic layer or the context layer that separates AI that is genuinely reliable from AI that is merely impressive.
An LLM with access to a well-built knowledge graph does not just retrieve better answers. It reasons differently by tracing relationships, surfacing hidden connections, and grounding every output in verifiable data rather than statistical plausibility.
In the next article, we turn to Pillar III: the infrastructure question. Having the right semantic layer is necessary but not sufficient. We will examine how data needs to be physically structured, stored, and accessible for AI agents to query this semantic layer at the speed and scale that modern banking decisions require.
In this series:
Pillar I: Data Freshness and Quality (published)
Pillar II: The Context Layer - Banking Ontology (published)
Pillar II continued: Knowledge Graphs for Banking AI (this article)
Pillar III: Accessibility and Infrastructure (coming soon)
Pillar IV: Governance, People and Skills (coming soon)
AI-Readiness Assessment Toolkit — Subscribe to get it first
Go Deeper
Foundations
Graph RAG
Limitations of RAG and how GraphRAG addresses them — FalkorDB
Grounding LLMs: The Knowledge Graph Foundation — Alessandro Negro
Banking and AI
Graph LLMs in Banking and Insurance — PwC 2024
Ontology-Constrained Reasoning in FinTech AI — arXiv 2025